Langgraph学习6:WebAgent支持网页内容抓取
在前面一篇Langgraph学习4的文章中,基本实现了一个能够进行Web搜索的AI助手。尽管搜索工具可以获取网络信息,但常常只返回搜索结果的简短摘要或链接,而不是完整内容。本篇我们将进一步扩展这个助手,让它能够抓取并分析网页内容,从而提供更深入的信息。
1. 搜索→抓取→总结的工作流
首先,需要设计一个更复杂的工作流:
chat_bot → search_tool → crawl4ai_tool → summary_bot → END以下是本篇代码跑通后的实际graph图例:
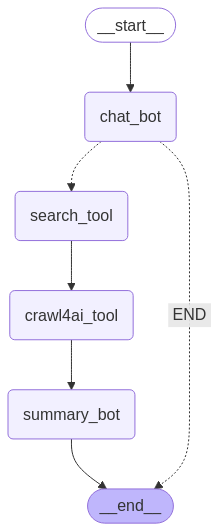
这个工作流包括四个主要节点:
- chat_bot:分析用户请求,决定是否需要搜索信息
- search_tool:执行网络搜索,获取相关链接
- crawl4ai_tool:抓取搜索返回的链接内容
- summary_bot:分析抓取的内容,生成综合回复
这种链式结构可以让我们实现”搜索→抓取→总结”的完整信息处理流程。
2. 网页抓取工具
首先需要实现一个网页抓取工具。这里我们使用一个自定义的网页爬虫工具:
from crawl_tool import quick_crawl_tool
@tool
async def crawl4ai_tool(query: list[str]):
"""用于爬取网页内容。接收URL列表,返回对应网页的内容。"""
urls = query
result = await quick_crawl_tool(urls)
return {"result": result}这个工具接收URL列表作为输入,返回抓取到的网页内容。使用async定义为异步函数,可以并行抓取多个网页,提高效率。
注意:这里依赖了自己封装的crea4ai的爬取工具 crawl_tool,该模块包含了爬虫的具体实现。
3. 爬取网页内容节点
接下来,我们需要实现爬取网页内容的节点:
async def crawl4ai_tool_node(state: MessagesState):
"""爬取网页内容工具节点"""
last_message = state["messages"][-1]
urls = last_message.content
# 调用爬虫工具获取结果
tool_response = await crawl4ai_tool.ainvoke({"query": urls})
messages = []
# 创建ToolMessage并添加到列表
messages.append(ToolMessage(
content=tool_response.get('result', tool_response),
tool_call_id=last_message.id
))
return {"messages": messages}这个节点函数的作用是:
- 从上一个节点(搜索工具)获取URL列表
- 调用网页抓取工具获取这些URL的内容
- 将抓取结果打包为ToolMessage返回
需要注意的是,这里我们假设搜索工具返回的是URL列表。在实际实现中可能需要进行更复杂的处理,例如从搜索结果中提取URL。
4. 总结节点
对抓取到的网页内容进行总结分析是关键步骤。我们使用另一个LLM实例来完成这个任务:
async def summary_bot_node(state: MessagesState):
"""总结网页内容的节点"""
messages = state["messages"]
# 找出用户的原始问题
human_messages = [msg for msg in messages if isinstance(msg, HumanMessage)]
human_message = human_messages[0] if human_messages else None
# 找出最后一个工具消息(包含抓取的网页内容)
tool_messages = [msg for msg in messages if isinstance(msg, ToolMessage)]
last_tool_message = None
for msg in reversed(tool_messages):
if msg.content:
last_tool_message = msg
break
# 创建系统消息
system_message = SystemMessage(content="""
## 你是一个擅长信息整理并总结的AI助手,请根据用户的问题,并结合工具给出的信息把回复总结出来。
- 如果有工具信息,正常执行总结;如果工具信息里是一些在线pdf,请把pdf的url和标题输出出来,告知用户来源自行查看。
- 如果发现工具没有返回信息,如【工具执行异常,无返回结果】,请根据用户的问题,给出简要回答,但必须带上说明,说明你无法生成详细总结的原因。并让用户再次自行尝试。
- 风格:排版按照markdown格式输出。热情,专业,有亲和力。
""")
# 构建消息列表
summary_messages = [system_message]
if human_message:
summary_messages.append(human_message)
if last_tool_message:
tool_result_message = ToolMessage(
content=f"以下是搜索和网页抓取工具返回的详细结果:\n\n{last_tool_message.content}",
tool_call_id=last_tool_message.id
)
summary_messages.append(tool_result_message)
# 调用摘要模型
if len(summary_messages) > 1:
response = await summary_llm.ainvoke(summary_messages)
else:
response = ToolMessage(
content="工具执行异常,无返回结果。",
tool_call_id=last_tool_message.id if last_tool_message else "error"
)
return {"messages": [response]}总结节点的工作流程是:
- 收集用户的原始问题
- 获取爬虫工具抓取的网页内容
- 构建一个精心设计的提示,要求模型根据用户问题和抓取内容生成总结
- 调用总结模型生成最终回复
使用单独的总结模型而不是直接让主模型继续回复有几个好处:
- 可以设计专门的提示,引导模型如何处理网页内容
- 避免主模型被过长的上下文困惑
- 便于单独优化总结功能
5. 修改搜索工具节点
我们需要修改搜索工具节点,使其专注于处理搜索请求并提取URL:
async def search_tool_node(state: dict):
"""搜索工具节点"""
result = []
for tool_call in state["messages"][-1].tool_calls:
if tool_call["name"] == "search_tool":
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
# 处理搜索结果,提取URL
if isinstance(observation, list):
urls = [item.get('url', '') for item in observation if isinstance(item, dict)]
search_result = urls
else:
search_result = observation
result.append(ToolMessage(content=search_result, tool_call_id=tool_call["id"]))
return {"messages": result}这个节点现在会检查工具名称是否为”search_tool”,然后执行搜索并从结果中提取URL。
这里需要注意: 如果使用的是TavilySearchResults,item里的链接字段是url,如果是使用的DuckDuckGoSearchResults,必须设置output_format=”list”,并且item里的链接字段是link。
另外,这里暂时没有处理非数组的情况,后续再进行完善~~
6. 构建完整工作流
现在我们可以构建完整的工作流:
# 添加节点到图
graph_builder.add_node("chat_bot", chatbot_node)
graph_builder.add_node("search_tool", search_tool_node)
graph_builder.add_node("crawl4ai_tool", crawl4ai_tool_node)
graph_builder.add_node("summary_bot", summary_bot_node)
# 设置入口点
graph_builder.set_entry_point("chat_bot")
# 添加条件边
graph_builder.add_conditional_edges(
"chat_bot",
route_search_tool,
path_map={"search_tool": "search_tool", "END": END}
)
# 添加其他边
graph_builder.add_edge("search_tool", "crawl4ai_tool")
graph_builder.add_edge("crawl4ai_tool", "summary_bot")
graph_builder.add_edge("summary_bot", END)与前一个版本不同,这次我们添加了一条明确的路径:从搜索工具到网页抓取工具,再到总结节点。这样确保了完整的信息处理流程。
工作流可视化如下:
7. 准备系统提示和测试问题
为了测试这个增强版助手,我们准备了一个关于专业知识的查询:
system_message_str = """
# 你是一个强大的AI助手,擅长搜索和分析网络信息。
## 对于用户的问题,请先分析是否有足够知识进行回答,否则就要进行网络查询。如果需要查询实时或专业信息,请先使用[搜索工具]获取相关内容的链接。
## 如果[搜索工具]返回的是链接,需要再用[爬虫工具]获取具体内容。
## 请牢记今天的日期是{today}。
"""
user_message_str = """
crawl4ai是什么?
"""这个系统提示明确指出了工作流程:先进行分析是否有足够知识进行回答,然后在进行网络搜索获取链接,再使用爬虫工具获取内容。
8. 监听事件流
在执行过程中,我们监听不同类型的事件,提供更透明的执行过程:
# 异步执行流式输出
async for event in graph.astream_events(initial_state, config={"configurable": {"thread_id": "8"}}, version="v2"):
# 定义一个变量接收所有on_chat_model_stream的值
# print('event------>',event,'\n\n')
event_type = event['event']
# print('event_type------>',event_type,'\n\n')
if event_type == 'on_tool_start' and event['data']:
print('开始调用工具查询', event['data'],'\n\n')
pass
elif event_type == 'on_tool_end' and event['data']:
print('工具查询结束',event['data'],'\n\n')
pass
elif event_type == 'on_chat_model_stream':
# print('on_chat_model_stream事件------>',event["data"]["chunk"].content,'\n\n')
chunk_data = event["data"]["chunk"].content # 流式输出的内容
output_list.append(chunk_data)
print(chunk_data, end='', flush=True)这里我们添加了对工具执行开始和结束事件的监听,这样用户可以看到后台工作流程。
9. 测试结果
当运行代码时,整个过程如下:
- LLM分析用户问题”crawl4ai是什么?”
- 决定这需要专业知识,调用搜索工具获取相关链接
- 搜索工具返回关于crawl4ai的信息网页链接
- 网页抓取工具获取这些链接的具体内容
- 总结模型分析内容,生成一个全面的crawl4ai的解释
复比单纯依赖搜索引擎摘要的回复更全面、更深入,因为它基于多个网页的完整内容,而不仅仅是搜索结果的摘要。
问题:
crawl4ai 是什么?
回答结果:
可以看到ai搜索工具调用结果返回的搜索到的链接是:https://zhuanlan.zhihu.com/p/2380440002
这个页面的文章长这样:
使用crawl4ai爬出的结果: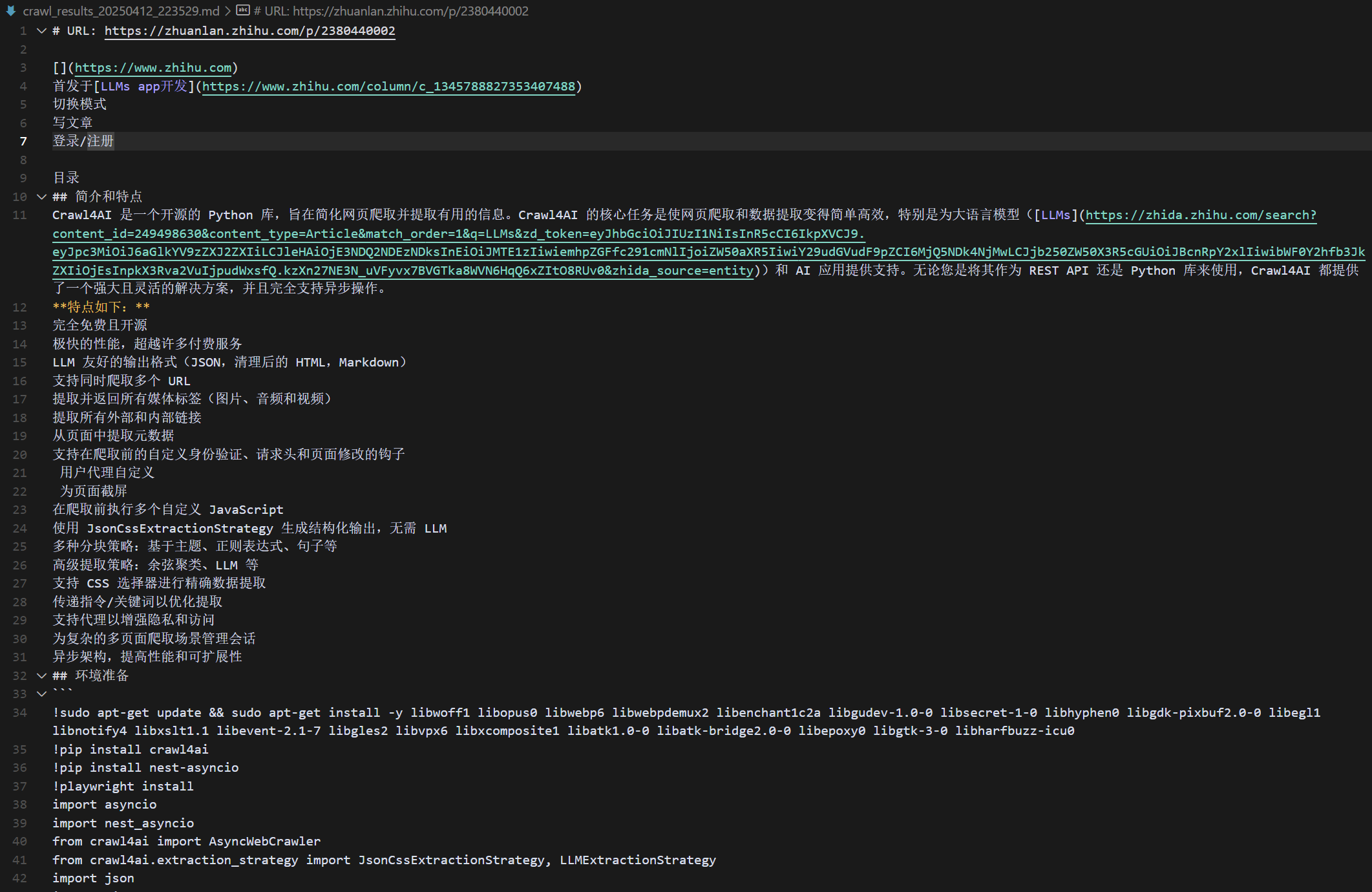
crawl4ai听起来像是一个团队或者项目的名字,但具体的含义或背景信息可能需要进一步的搜索来确定。让我帮您查找一下相关信息。
Crawl4AI 简介
Crawl4AI 是一个开源的 Python 库,主要用于简化网页爬取和提取信息。它旨在帮助用户高效地完成网页爬取任务,尤其适用于大语言模型(LLMs)和 AI 应用。Crawl4AI 可以作为 REST API 或 Python 库使用,支持异步操作,并提供了一系列强大的功能。
主要特点
- 免费且开源:Crawl4AI 是完全免费的,并且代码是开源的。
- 高性能:其性能超越了许多付费服务。
- LLM 友好:输出格式包括 JSON、清理后的 HTML 和 Markdown,便于 LLM 处理。
- 多 URL 爬取:支持同时爬取多个 URL。
- 媒体和链接提取:可以提取所有媒体标签(图片、音频和视频)以及外部和内部链接。
- 元数据提取:从页面中提取元数据。
- 自定义功能:支持自定义身份验证、请求头和页面修改的钩子。
- 用户代理和页面截屏:支持用户代理自定义和页面截屏。
- JavaScript 执行:在爬取前可以执行多个自定义 JavaScript。
- 结构化输出:使用 JsonCssExtractionStrategy 生成结构化输出。
- 多种分块策略:支持基于主题、正则表达式、句子等的分块策略。
- 高级提取策略:包括余弦聚类、LLM 等。
- CSS 选择器:支持 CSS 选择器进行精确数据提取。
- 指令/关键词优化:可以通过传递指令/关键词来优化提取。
- 代理支持:支持代理以增强隐私和访问。
- 会话管理:为复杂的多页面爬取场景管理会话。
- 异步架构:提高性能和可扩展性。
环境准备
要使用 Crawl4AI,需要安装一些依赖库和软件,包括 > Python、pip、playwright 等。
基础使用
Crawl4AI 提供了简单的 API 来提取网页内容。例如,可> 以使用
AsyncWebCrawler类来爬取网页,并打印出提> 取的 Markdown 内容。高级使用
Crawl4AI 还支持更高级的功能,如执行 JavaScript 脚> 本、使用 CSS 选择器进行数据提取等。
结构化数据提取
Crawl4AI 的 JsonCssExtractionStrategy 功能允许从> 网页中精确提取结构化数据,这对于从产品列表、新闻文> 章或搜索结果等页面中提取数据非常有用。
总结
Crawl4AI 是一个功能强大的网页爬取和提取工具,适用> 于各种爬取任务,特别是对于需要处理大量数据的 LLM > 和 AI 应用。它提供了丰富的功能和灵活的配置选项,使> 得用户可以轻松地完成复杂的爬 取任务。
来源:
- [GitHub - unclecode/crawl4ai: ️ Crawl4AI: > Open-source LLM Friendly Web Crawler & > Scrapper](https://link.zhihu.com/?> target=https%3A//github.com/unclecode/crawl4ai)
- [Home - Crawl4AI Documentation](https://link.> zhihu.com/?target=https%3A//crawl4ai.com/> mkdocs/)
以下是完整log:
开始流式生成回答...
crawl4ai听起来像是一个团队或者项目的名字,但具体的含义或背景信息可能需要进一步的搜索来确定。让我帮您查找一下相关信息。
搜索工具结果的完整输出------> [{'title': 'Crawl4AI:基于LLMs 的高效爬虫工具 - 知乎专栏', 'url': 'https://zhuanlan.zhihu.com/p/2380440002', 'content': 'Crawl4AI 是一个开源的Python 库,旨在简化网页爬取并提取有用的信息。Crawl4AI 的核心任务是使网页爬取和数据提取变得简单高效,特别是为大语言模型(LLMs)和AI 应用', 'score': 0.6612456}]
开始调用工具查询 {'input': {'query': 'crawl4ai 是什么'}}
开始调用工具查询 {'input': {}}
工具查询结束 {'output': [{'title': 'Crawl4AI:基于LLMs 的高效爬虫工具 - 知乎专栏', 'url': 'https://zhuanlan.zhihu.com/p/2380440002', 'content': 'Crawl4AI 是一个开源的Python 库,旨在简化网页爬取并提取有用的信息。Crawl4AI 的核心任务是使网页爬取和数据提取变得简单高效,特别是为大语言模型(LLMs)和AI 应用', 'score': 0.6612456}], 'input': None}
工具查询结束 {'output': [{'title': 'Crawl4AI:基于LLMs 的高效爬虫工具 - 知乎专栏', 'url': 'https://zhuanlan.zhihu.com/p/2380440002', 'content': 'Crawl4AI 是一个开源的Python 库,旨在简化网页爬取并提取有用的信息。Crawl4AI 的核心任务是使网页爬取和数据提取变得简单高效,特别是为大语言模型(LLMs)和AI 应用', 'score': 0.6612456}], 'input': {'query': 'crawl4ai 是什么'}}
开始调用工具查询 {'input': {'query': ['https://zhuanlan.zhihu.com/p/2380440002']}}
crawl4ai_tool收到的完整输入------> ['https://zhuanlan.zhihu.com/p/2380440002']
urls------> ['https://zhuanlan.zhihu.com/p/2380440002']
[INIT].... → Crawl4AI 0.5.0.post4
[FETCH]... ↓ https://zhuanlan.zhihu.com/p/2380440002... | Status: True | Time: 2.50s
[SCRAPE].. ◆ https://zhuanlan.zhihu.com/p/2380440002... | Time: 0.102s
[COMPLETE] ● https://zhuanlan.zhihu.com/p/2380440002... | Status: True | Total: 2.62s
[OK] https://zhuanlan.zhihu.com/p/2380440002, length: 9849
所有结果已保存到文件: crawl_results_20250412_223529.md
工具查询结束 {'output': {'result': '[](https://www.zhihu.com)\n首发于[LLMs app开发](https://www.zhihu.com/column/c_1345788827353407488)\n切换模式\n写文章\n登录/注册\n\u200b\n目
录\n## 简介和特点\nCrawl4AI 是一个开源的 Python 库,旨在简化网页爬取并提取有用的信息。Crawl4AI 的核心任务是使网页爬取和数据提取变得简单高效,特别是为大语言模型([LLMs](https://zhida.zhihu.com/search?content_id=249498630&content_type=Article&match_order=1&q=LLMs&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDQ2NDEzNDksInEiOiJMTE1zIiwiemhpZGFfc291cmNlIjoiZW50aXR5IiwiY29udGVudF9pZCI6MjQ5NDk4NjMwLCJjb250ZW50X3R5cGUiOiJBcnRpY2xlIiwibWF0Y2hfb3JkZXIiOjEsInpkX3Rva2VuIjpudWxsfQ.kzXn27NE3N_uVFyvx7BVGTka8WVN6HqQ6xZItO8RUv0&zhida_source=entity))和 AI 应用提供支持。无论您是将其作为 REST API 还是 Python 库来使用,Crawl4AI 都提供了一个强大且灵活的解决方案,并且完全支持异步操作。\n**特点如下:**\n完全免费且开源\n极快的性能,超越许多付费服务\nLLM 友好的输出格式(JSON,清理后的 HTML,Markdown)\n支持同时爬取多个 URL\n提取并返回所有媒体标签(图片、音频和视频)\n提取所有外部和内部链接\n从页面中提取元数据\n支持在爬取前的自定义身份验证、请求头和页面修改的钩子\n️ 用户代理自定义\n️ 为页面截屏\n在爬取前执行多个自定义 JavaScript\n n使用 JsonCssExtractionStrategy 生成结构化输出,无需 LLM\n多种分块策略:基于主题、正则表达式、句子等\n高级提取策略:余弦聚类、LLM 等\n支持 CSS 选择器进行精确数据提取\n传递指令/关键词以优化提取\n支持代理以增强隐私和访问\n为复杂的多页面爬取场景管理会话\n异步架构,提高性能和可扩展性\n## 环境准备\n```\n!sudo apt-get update && sudo apt-get install -y libwoff1 libopus0 libwebp6 libwebpdemux2 libenchant1c2a libgudev-1.0-0 libsecret-1-0 libhyphen0 libgdk-pixbuf2.0-0 libegl1 libnotify4 libxslt1.1 libevent-2.1-7 libgles2 libvpx6 libxcomposite1 libatk1.0-0 libatk-bridge2.0-0 libepoxy0 libgtk-3-0 libharfbuzz-icu0\n!pip install crawl4ai\n!pip install nest-asyncio\n!playwright install\nimport asyncio\nimport nest_asyncio\nfrom crawl4ai import AsyncWebCrawler\nfrom crawl4ai.extraction_strategy import JsonCssExtractionStrategy, LLMExtractionStrategy\nimport json\nimport time\nfrom pydantic import BaseModel, Field\nnest_asyncio.apply()\n```\n\n## 基础使用:提取网页内容\n```\nasync def simple_crawl():\n async with AsyncWebCrawler(verbose=True) as crawler:\n result = await crawler.arun(url="https://www.nbcnews.com/business")\n print()\n print(len(result.markdown))\n print(result.markdown[:500])\nawait simple_crawl()\n```\n\n爬取结果:\n## 高级使用:JS 脚本执行和CSS选择器的使用\n```\nasync def js_and_css():\n print("\\n--- Executing JavaScript and Using CSS Selectors ---")\n # New code to handle the wait_for parameter\n wait_for = """() => {\n return Array.from(document.querySelectorAll(\'article.tease-card\')).length > 10;\n }"""\n # wait_for can be also just a css selector\n # wait_for = "article.tease-card:nth-child(10)"\n async with AsyncWebCrawler(verbose=True) as crawler:\n js_code = [\n "const loadMoreButton = Array.from(document.querySelectorAll(\'button\')).find(button => button.textContent.includes(\'Load More\')); loadMoreButton && loadMoreButton.click();"\n ]\n result = await crawler.arun(\n url="https://www.nbcnews.com/business",\n js_code=js_code,\n css_selector="article.tease-card",\n # wait_for=wait_for,\n bypass_cache=True,\n )\n print(result.markdown[:500]) # Print first 500 characters\nawait js_and_css()\n```\n\n## gpt-4o 结构化数据提取\n```\nimport os\nfrom google.colab import userdata\n#os.environ[\'OPENAI_API_KEY\'] = userdata.get(\'OPENAI_API_KEY\')\nos.environ[\'OPENAI_API_KEY\'] = "sk-xxxx" ## 请输入你个人的 api key\n \nclass OpenAIModelFee(BaseModel):\n model_name: str = Field(..., description="Name of the OpenAI model.")\n input_fee: str = Field(..., description="Fee for input token for the OpenAI model.")\n output_fee: str = Field(..., description="Fee for output token for the OpenAI model.")\nasync def extract_openai_fees():\n async with AsyncWebCrawler(verbose=True) as crawler:\n result = await crawler.arun(\n url=\'https://openai.com/api/pricing/\',\n word_count_threshold=1,\n extraction_strategy=LLMExtractionStrategy(\n provider="openai/gpt-4o-2024-08-06", api_token=os.getenv(\'OPENAI_API_KEY\'),\n schema=OpenAIModelFee.schema(),\n extraction_type="schema",\n instruction="""From the crawled content, extract all mentioned model names along with their fees for input and output tokens.\n Do not miss any models in the entire content. One extracted model JSON format should look like this:\n {"model_name": "GPT-4", "input_fee": "US$10.00 / 1M tokens", "output_fee": "US$30.00 / 1M tokens"}."""\n ),\n bypass_cache=True,\n )\n print(len(result.extracted_content))\n print(result.extracted_content)\n# Uncomment the following line to run the OpenAI extraction example\nawait extract_openai_fees()\n```\n\n返回的结果:\n## JS 脚本执行+多页内容爬取\n下面的案例展示了 Crawl4AI 处理复杂爬取场景的能力,特别是从 GitHub 仓库的多个页面中提取提交记录。这里的挑战在于,点击"下一页"按钮并不会加载新页面,而是使用异步 JavaScript 来更新内容。这在现代网页爬取中是一个常见的难题。\n为了解决这个问题,我们使用了 Crawl4AI 的自定义 JavaScript 执行功能,模拟点击"下一页"按钮 ,并实现了一个自定义钩子来检测新数据是否加载。我们的策略是比较点击"下一页"前后第一个提交记录的文本,等待其变化,以确认新数据已呈现。这展示了 Crawl4AI 在处理动态内容时的灵活性, 以及在面对最具挑战性的爬取任务时实现自定义逻辑的能力。\n```\nimport re\nfrom bs4 import BeautifulSoup\nasync def crawl_dynamic_content_pages_method_3():\n print("\\n--- Advanced Multi-Page Crawling with JavaScript Execution using `wait_for` ---")\n async with AsyncWebCrawler(verbose=True) as crawler:\n url = "https://github.com/microsoft/TypeScript/commits/main"\n session_id = "typescript_commits_session"\n all_commits = []\n js_next_page = """\n const commits = document.querySelectorAll(\'li.Box-sc-g0xbh4-0 h4\');\n if (commits.length > 0) {\n window.firstCommit = commits[0].textContent.trim();\n }\n const button = document.querySelector(\'a[data-testid="pagination-next-button"]\');\n if (button) button.click();\n """\n wait_for = """() => {\n const commits = document.querySelectorAll(\'li.Box-sc-g0xbh4-0 h4\');\n if (commits.length === 0) return false;\n const firstCommit = commits[0].textContent.trim();\n return firstCommit !== window.firstCommit;\n }"""\n schema = {\n "name": "Commit Extractor",\n "baseSelector": "li.Box-sc-g0xbh4-0",\n "fields": [\n {\n "name": "title",\n "selector": "h4.markdown-title",\n "type": "text",\n "transform": "strip",\n },\n ],\n }\n extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)\n for page in range(3): # Crawl 3 pages\n result = await crawler.arun(\n url=url,\n session_id=session_id,\n css_selector="li.Box-sc-g0xbh4-0",\n extraction_strategy=extraction_strategy,\n js_code=js_next_page if page > 0 else None,\n wait_for=wait_for if page > 0 else None,\n js_only=page > 0,\n bypass_cache=True,\n headless=False,\n )\n assert result.success, f"Failed to crawl page {page + 1}"\n commits = json.loads(result.extracted_content)\n all_commits.extend(commits)\n print(f"Page {page + 1}: Found {len(commits)} commits")\n await crawler.crawler_strategy.kill_session(session_id)\n print(f"Successfully crawled {len(all_commits)} commits across 3 pages")\nawait crawl_dynamic_content_pages_method_3()\n```\n\n爬取结果:\n## JsonCss 提取和快速结构化输出\nJsonCssExtractionStrategy 是 Crawl4AI 的一个强大功能,允许从网页中精确提取结构化数据。其工作原理如下:\n 1. 你定义一个描述所需数据提取模式的模式(schema)。\n 2. 该模式包括一个基础选择器,用于标识页面上重复的 元素。\n 3. 在模式中,你可以定义字段,每个字段都有自己的选择器和类型。\n 4. 这些字段选择器将在每个基础选择器元素的上下文中应用。\n 5. 该策略支持嵌套结构、列表中的列表和各种数据类型。\n 6. 你甚至可以包含计算字段来进行更复杂的数据处理。\n\n\n这种方法允许高度灵活和精确的数据提取,将半结构化的网页内容转化为干净、结构化的 JSON 数据。它在从产品列表、新闻文章或搜索结果等页面中提取一致数据模式时尤其有用。\n```\nasync def extract_news_teasers():\n schema = {\n "name": "News Teaser Extractor",\n "baseSelector": ".wide-tease-item__wrapper",\n "fields": [\n {\n "name": "category",\n "selector": ".unibrow span[data-testid=\'unibrow-text\']",\n "type": "text",\n },\n {\n "name": "headline",\n "selector": ".wide-tease-item__headline",\n "type": "text",\n },\n {\n "name": "summary",\n "selector": ".wide-tease-item__description",\n "type": "text",\n },\n {\n "name": "time",\n "selector": "[data-testid=\'wide-tease-date\']",\n "type": "text",\n },\n {\n "name": "image",\n "type": "nested",\n "selector": "picture.teasePicture img",\n "fields": [\n {"name": "src", "type": "attribute", "attribute": "src"},\n {"name": "alt", "type": "attribute", "attribute": "alt"},\n ],\n },\n {\n "name": "link",\n "selector": "a[href]",\n "type": "attribute",\n "attribute": "href",\n },\n ],\n }\n extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)\n async with AsyncWebCrawler(verbose=True) as crawler:\n result = await crawler.arun(\n url="https://www.nbcnews.com/business",\n extraction_strategy=extraction_strategy,\n bypass_cache=True,\n )\n assert result.success, "Failed to crawl the page"\n news_teasers = json.loads(result.extracted_content)\n print(f"Successfully extracted {len(news_teasers)} news teasers")\n print(json.dumps(news_teasers[0], indent=2))\nawait extract_news_teasers()\n```\n\n结果如下:\n来源:[GitHub - unclecode/crawl4ai: ️ Crawl4AI: Open-source LLM Friendly Web Crawler & Scrapper](https://link.zhihu.com/?target=https%3A//github.com/unclecode/crawl4ai)\n官网:[Home - Crawl4AI Documentatiion](https://link.zhihu.com/?target=https%3A//crawl4ai.com/mkdocs/)\n编辑于 2024-10-22 07:20・美国\n[大模型](https://www.zhihu.com/topic/25402720)\n[爬虫](https://www.zhihu.com/topic/20049326)\n[AI](https://www.zhihu.com/topic/19588023)\n\u200b赞同 19\u200b\u200b10 条评论\n\u200b分享\n\u200b喜欢\u200b收藏\u200b申请转载\n\u200b\n暂无评论\n### 推荐阅读\n# [【Python】爬虫篇 Selenium运用你熟练到了什么程度?奔跑的蜗牛](https://zhuanlan.zhihu.com/p/441080010)# [Python爬虫——Selenium基础教程——准备苏小菁在编...发表于苏小菁在编...](https://zhuanlan.zhihu.com/p/137710454)# [别上来就爬,写爬虫也有模式和套路图灵君](https://zhuanlan.zhihu.com/p/62863150)# [【Python爬虫奇淫技巧】用pandas库read_html函数一行代码搞定 爬虫!马哥pyt...发表于马哥Pyt...](https://zhuanlan.zhihu.com/p/445464339)\n\n_想来知乎工作?请发送邮件到 jobs@zhihu.com_\n打开知乎App\n在「我的页」右上角打开扫一扫\n其他扫码方式:微信\n下载知乎App\n[开通机构号](https://zhuanlan.zhihu.com/org/signup)\n无障碍模式\n其他方式登录\n未注册手机验证后自动登录,注册即代表同意[《知乎协议》](https://www.zhihu.com/term/zhihu-terms)[《隐私保护指引》](https://www.zhihu.com/term/privacy)\n扫码下载知乎 App\n关闭二维码\n\n\n'}, 'input': {'query': ['https://zhuanlan.zhihu.com/p/2380440002']}}
### Crawl4AI 简介
Crawl4AI 是一个开源的 Python 库,主要用于简化网页爬取和提取信息。它旨在帮助用户高效地完成网页爬取任务,尤其适用于大语言模型(LLMs)和 AI 应用。Crawl4AI 可以作为 REST API 或 Python 库使用,支持异步操作,并提供了一系列强大的功能。
### 主要特点
- **免费且开源**:Crawl4AI 是完全免费的,并且代码是开源的。
- **高性能**:其性能超越了许多付费服务。
- **LLM 友好**:输出格式包括 JSON、清理后的 HTML 和 Markdown,便于 LLM 处理。
- **多 URL 爬取**:支持同时爬取多个 URL。
- **媒体和链接提取**:可以提取所有媒体标签(图片、音频和视频)以及外部和内部链接。
- **元数据提取**:从页面中提取元数据。
- **自定义功能**:支持自定义身份验证、请求头和页面修改的钩子。
- **用户代理和页面截屏**:支持用户代理自定义和页面截屏。
- **JavaScript 执行**:在爬取前可以执行多个自定义 JavaScript。
- **结构化输出**:使用 JsonCssExtractionStrategy 生成结构化输出。
- **多种分块策略**:支持基于主题、正则表达式、句子等的分块策略。
- **高级提取策略**:包括余弦聚类、LLM 等。
- **CSS 选择器**:支持 CSS 选择器进行精确数据提取。
- **指令/关键词优化**:可以通过传递指令/关键词来优化提取。
- **代理支持**:支持代理以增强隐私和访问。
- **会话管理**:为复杂的多页面爬取场景管理会话。
- **异步架构**:提高性能和可扩展性。
### 环境准备
要使用 Crawl4AI,需要安装一些依赖库和软件,包括 Python、pip、playwright 等。
### 基础使用
Crawl4AI 提供了简单的 API 来提取网页内容。例如,可以使用 `AsyncWebCrawler` 类来爬取网页,并打印出提取的 Markdown 内容。
### 高级使用
Crawl4AI 还支持更高级的功能,如执行 JavaScript 脚本、使用 CSS 选择器进行数据提取等。
### 结构化数据提取
Crawl4AI 的 JsonCssExtractionStrategy 功能允许从网页中精确提取结构化数据,这对于从产品列表、新闻文章或搜索结果等页面中提取数据非常有用。
### 总结
Crawl4AI 是一个功能强大的网页爬取和提取工具,适用于各种爬取任务,特别是对于需要处理大量数据的 LLM 和 AI 应用。它提供了丰富的功能和灵活的配置选项,使得用户可以轻松地完成复杂的爬 取任务。
**来源**:
- [GitHub - unclecode/crawl4ai: ️ Crawl4AI: Open-source LLM Friendly Web Crawler & Scrapper](https://link.zhihu.com/?target=https%3A//github.com/unclecode/crawl4ai)
- [Home - Crawl4AI Documentation](https://link.zhihu.com/?target=https%3A//crawl4ai.com/mkdocs/)
************************************************************************************************************************
生成完成!
crawl4ai听起来像是一个团队或者项目的名字,但具体的含义或背景信息可能需要进一步的搜索来确定。让我帮您查找一下相关信息。
### Crawl4AI 简介
Crawl4AI 是一个开源的 Python 库,主要用于简化网页爬取和提取信息。它旨在帮助用户高效地完成网页爬取任务,尤其适用于大语言模型(LLMs)和 AI 应用。Crawl4AI 可以作为 REST API 或 Python 库使用,支持异步操作,并提供了一系列强大的功能。
### 主要特点
- **免费且开源**:Crawl4AI 是完全免费的,并且代码是开源的。
- **高性能**:其性能超越了许多付费服务。
- **LLM 友好**:输出格式包括 JSON、清理后的 HTML 和 Markdown,便于 LLM 处理。
- **多 URL 爬取**:支持同时爬取多个 URL。
- **媒体和链接提取**:可以提取所有媒体标签(图片、音频和视频)以及外部和内部链接。
- **元数据提取**:从页面中提取元数据。
- **自定义功能**:支持自定义身份验证、请求头和页面修改的钩子。
- **用户代理和页面截屏**:支持用户代理自定义和页面截屏。
- **JavaScript 执行**:在爬取前可以执行多个自定义 JavaScript。
- **结构化输出**:使用 JsonCssExtractionStrategy 生成结构化输出。
- **多种分块策略**:支持基于主题、正则表达式、句子等的分块策略。
- **高级提取策略**:包括余弦聚类、LLM 等。
- **CSS 选择器**:支持 CSS 选择器进行精确数据提取。
- **指令/关键词优化**:可以通过传递指令/关键词来优化提取。
- **代理支持**:支持代理以增强隐私和访问。
- **会话管理**:为复杂的多页面爬取场景管理会话。
- **异步架构**:提高性能和可扩展性。
### 环境准备
要使用 Crawl4AI,需要安装一些依赖库和软件,包括 Python、pip、playwright 等。
### 基础使用
Crawl4AI 提供了简单的 API 来提取网页内容。例如,可以使用 `AsyncWebCrawler` 类来爬取网页,并打印出提取的 Markdown 内容。
### 高级使用
Crawl4AI 还支持更高级的功能,如执行 JavaScript 脚本、使用 CSS 选择器进行数据提取等。
### 结构化数据提取
Crawl4AI 的 JsonCssExtractionStrategy 功能允许从网页中精确提取结构化数据,这对于从产品列表、新闻文章或搜索结果等页面中提取数据非常有用。
### 总结
Crawl4AI 是一个功能强大的网页爬取和提取工具,适用于各种爬取任务,特别是对于需要处理大量数据的 LLM 和 AI 应用。它提供了丰富的功能和灵活的配置选项,使得用户可以轻松地完成复杂的爬 取任务。
**来源**:
- [GitHub - unclecode/crawl4ai: ️ Crawl4AI: Open-source LLM Friendly Web Crawler & Scrapper](https://link.zhihu.com/?target=https%3A//github.com/unclecode/crawl4ai)
- [Home - Crawl4AI Documentation](https://link.zhihu.com/?target=https%3A//crawl4ai.com/mkdocs/)
************************************************************************************************************************这里需要说明一下,如果问的是一些比如2024年AI发展报告,搜索工具会返回一些.pdf结尾的在线pdf页面,这种的话目前crawl4ai是无法爬取的,不过在GitHub上以看到有人提了这个问题,也回复了后续会更新相关功能,所以这里只是简单通过pormpt做了一些处理,比如如果爬取工具没有返回内容就直接将pdf的链接返回出来。
以下是完整代码:
from datetime import datetime
import os
import sys
from dotenv import load_dotenv
load_dotenv()
import asyncio
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.tools.ddg_search.tool import DuckDuckGoSearchResults
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, SystemMessage, ToolMessage
from langgraph.graph import StateGraph, START, END, MessagesState
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_core.runnables.graph import MermaidDrawMethod
from langchain_core.messages import ToolMessage
from langchain_core.tools import tool
# 添加项目根目录到Python路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from crawl_tool import quick_crawl_tool
# 创建图构建器
graph_builder = StateGraph(MessagesState)
os.environ['TAVILY_API_KEY'] = os.getenv('TAVILY_API_KEY', '')
# 创建工具
@tool
def search_tool(query: str):
"""用于浏览网络进行搜索。"""
search_tool = TavilySearchResults(max_results=1)
# search_tool = DuckDuckGoSearchResults(num_results=1, output_format="list") # output_format="list"
return search_tool.invoke(query)
@tool
async def crawl4ai_tool(query: list[str]):
"""用于爬取网页内容。接收URL列表,返回对应网页的内容。"""
print('crawl4ai_tool收到的完整输入------>',query,'\n')
urls = query
result = await quick_crawl_tool(urls)
return {"result": result}
tools = [search_tool, crawl4ai_tool]
# 创建llm,需要支持FunctionCalling的模型
llm = ChatOpenAI(
#THUDM/glm-4-9b-chat
#Qwen/Qwen2.5-7B-Instruct
model="Qwen/Qwen2.5-7B-Instruct",
streaming=False, # 启用流式输出
api_key=os.getenv('SILICONFLOW_API_KEY', ''),
base_url=os.getenv('SILICONFLOW_BASE_URL', ''),
temperature=0.1,
)
llm_with_tools = llm.bind_tools(tools)
# 创建总结llm,需要使用支持FunctionCalling的模型
summary_llm = ChatOpenAI(
model="THUDM/glm-4-9b-chat",
streaming=False,
api_key=os.getenv('SILICONFLOW_API_KEY', ''),
base_url=os.getenv('SILICONFLOW_BASE_URL', ''),
temperature=0.1,
)
# 创建工具列表的函数版本
functions = [convert_to_openai_function(t) for t in tools]
tools_by_name = {tool.name: tool for tool in tools}
# 定义搜索工具节点函数
async def search_tool_node(state: dict):
"""搜索工具节点"""
result = []
for tool_call in state["messages"][-1].tool_calls:
if tool_call["name"] == "search_tool":
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
print('搜索工具结果的完整输出------>',observation,'\n')
if isinstance(observation, list):
# 如果是数组,直接提取每个对象的URL
urls = [item.get('url', '') for item in observation if isinstance(item, dict)]
search_result = urls
else:
# 如果不是数组,将整个observation作为结果
search_result = str(observation)
result.append(ToolMessage(content=search_result, tool_call_id=tool_call["id"]))
return {"messages": result}
# 爬取网页内容工具节点
async def crawl4ai_tool_node(state: MessagesState):
"""爬取网页内容工具节点"""
last_message = state["messages"][-1]
urls = last_message.content
# 调用爬虫工具获取结果
tool_response = await crawl4ai_tool.ainvoke({"query": urls})
messages = []
# 创建ToolMessage并添加到列表
messages.append(ToolMessage(
content=tool_response.get('result', tool_response),
tool_call_id=last_message.id
))
return {"messages": messages}
# 定义流式节点函数
async def chatbot_node(state: MessagesState):
"""生成回复的节点函数"""
messages = state["messages"]
# 使用非流式方式接收完整返回
response = await llm_with_tools.ainvoke(
messages,
functions=functions,
function_call="auto"
)
return {"messages": [response]}
# 总结bot节点
async def summary_bot_node(state: MessagesState):
"""总结网页内容的节点"""
messages = state["messages"]
# 找出用户的原始问题
human_messages = [msg for msg in messages if isinstance(msg, HumanMessage)]
human_message = human_messages[0] if human_messages else None
# 找出最后一个工具消息(包含抓取的网页内容)
tool_messages = [msg for msg in messages if isinstance(msg, ToolMessage)]
last_tool_message = None
for msg in reversed(tool_messages):
if msg.content:
last_tool_message = msg
break
# 创建系统消息
system_message = SystemMessage(content="""
## 你是一个擅长信息整理并总结的AI助手,请根据用户的问题,并结合工具给出的信息把回复总结出来。
- 如果有工具信息,正常执行总结;如果工具信息里是一些在线pdf,请把pdf的url和标题输出出来,告知用户来源自行查看。
- 如果发现工具没有返回信息,如【工具执行异常,无返回结果】,请根据用户的问题,给出简要回答,但必须带上说明,说明你无法生成详细总结的原因。并让用户再次自行尝试。
- 风格:排版按照markdown格式输出。热情,专业,有亲和力。
""")
# 构建消息列表
summary_messages = [system_message]
if human_message:
summary_messages.append(human_message)
if last_tool_message:
tool_result_message = ToolMessage(
content=f"以下是搜索和网页抓取工具返回的详细结果:\n\n{last_tool_message.content}",
tool_call_id=last_tool_message.id
)
summary_messages.append(tool_result_message)
# 调用摘要模型
if len(summary_messages) > 1:
response = await summary_llm.ainvoke(summary_messages)
else:
response = ToolMessage(
content="工具执行异常,无返回结果。",
tool_call_id=last_tool_message.id if last_tool_message else "error"
)
return {"messages": [response]}
def route_search_tool(state: MessagesState):
"""
在条件边中使用,如果最后一条消息包含搜索工具调用,则路由到搜索工具节点,否则路由到结束节点。
"""
messages = state['messages']
last_message = messages[-1]
# 检查是否是AI消息且有工具调用
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
for tool_call in last_message.tool_calls:
if tool_call["name"] == "search_tool":
return "search_tool"
return END
# 添加节点到图
graph_builder.add_node("chat_bot", chatbot_node)
graph_builder.add_node("search_tool", search_tool_node)
graph_builder.add_node("crawl4ai_tool", crawl4ai_tool_node)
graph_builder.add_node("summary_bot", summary_bot_node)
# 设置入口点
graph_builder.set_entry_point("chat_bot")
# 添加条件边
graph_builder.add_conditional_edges(
"chat_bot",
route_search_tool,
path_map={"search_tool": "search_tool", "END": END}
)
# 添加其他边
graph_builder.add_edge("search_tool", "crawl4ai_tool")
graph_builder.add_edge("crawl4ai_tool", "summary_bot")
graph_builder.add_edge("summary_bot", END)
# 编译图
graph = graph_builder.compile()
# 定义一个将图导出为PNG的函数
def export_graph_to_png():
"""
将LangGraph图导出为PNG格式
Returns:
str: 生成的PNG文件路径
"""
try:
output_file='web_crawl_graph-' + datetime.now().strftime("%Y-%m-%d_%H-%M-%S") + ".png"
graph.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API,
output_file_path=output_file
)
except Exception as e:
print(f"导出PNG图形时出错: {e}")
return None
# 异步运行函数
async def run_demo():
"""异步运行LangGraph流式输出演示"""
print("开始流式生成回答...\n")
today = datetime.now().strftime("%Y-%m-%d")
# 创建初始消息
system_message = SystemMessage(content=f"""
# 你是一个强大的AI助手,擅长搜索和分析网络信息。
## 对于用户的问题,请先分析是否有足够知识进行回答,否则就要进行网络查询。如果需要查询实时或专业信息,请先使用[搜索工具]获取相关内容的链接。
## 如果[搜索工具]返回的是链接,需要再用[爬虫工具]获取具体内容。
## 请牢记今天的日期是{today}。
""")
first_message = HumanMessage(content="""
crawl4ai是什么?
""")
# 初始化状态
initial_state = {"messages": [system_message, first_message]}
output_list = []
try:
# 异步执行流式输出
async for event in graph.astream_events(initial_state, config={"configurable": {"thread_id": "8"}}, version="v2"):
# 定义一个变量接收所有on_chat_model_stream的值
# print('event------>',event,'\n\n')
event_type = event['event']
# print('event_type------>',event_type,'\n\n')
if event_type == 'on_tool_start' and event['data']:
print('开始调用工具查询', event['data'],'\n\n')
pass
elif event_type == 'on_tool_end' and event['data']:
print('工具查询结束',event['data'],'\n\n')
pass
elif event_type == 'on_chat_model_stream':
# print('on_chat_model_stream事件------>',event["data"]["chunk"].content,'\n\n')
chunk_data = event["data"]["chunk"].content # 流式输出的内容
output_list.append(chunk_data)
print(chunk_data, end='', flush=True)
except Exception as e:
print(f"graph.astream_events执行出错: {e}")
print('\n\n')
print('************'*10)
print("生成完成!\n","".join(output_list),'\n\n')
print('************'*10)
# 展示图形
try:
mermaid_diagram = graph.get_graph().draw_mermaid()
print(f"```mermaid\n{mermaid_diagram}\n```")
export_graph_to_png()
except Exception as e:
print(f"图表绘制出错: {e}")
# 执行异步函数
if __name__ == "__main__":
asyncio.run(run_demo())10. 总结与思考
(以下为Claude-3.7-sonnet根据6篇博客的一个总结)
通过前六篇Langgraph学习系列,从最基础的聊天机器人开始,逐步构建出一个能够进行网络搜索和网页内容抓取的复杂AI助手。回顾整个学习过程,可以总结如下几点:
Langgraph工作流理解
- 节点与状态图:Langgraph的核心是基于节点和边的状态图,每个节点负责特定功能,通过边连接形成工作流。
- 状态传递机制:各节点间通过状态字典传递信息,保证数据在整个工作流中的连贯性。
- 条件路由:通过条件函数动态决定执行路径,实现复杂的决策逻辑。
- 事件监听:通过
astream_events可监听整个工作流的执行过程,包括节点开始、结束、中间输出等。
技术演进路线
- 基础聊天机器人:实现了简单的用户问答功能(第1篇)
- 工具调用集成:让LLM能够根据需要调用工具(第2篇)
- 搜索工具对比:探索不同搜索API的特点和适用场景(第3篇)
- Web搜索集成:构建能够搜索网络信息的AI助手(第4篇)
- ai爬取工具的使用:集成Crawl4AI等专为大语言模型设计的爬虫工具,实现对网页内容的高效抓取(第5篇)
- 网页内容抓取:扩展助手能力,实现对网页内容的深度分析(第6篇)
关键技术点
- 工具函数封装:使用
@tool装饰器将普通函数转化为LLM可调用的工具。 - 自定义节点:根据不同需求实现特定功能的节点函数。
- 格式处理:解决工具返回结果与LLM兼容性问题。
- System Prompt设计:精心设计系统提示,引导LLM正确使用工具。
- 链式处理:实现”搜索→抓取→总结”的完整信息处理流程。
实用价值
通过这个系列,我们构建了一个实用的AI助手,它不仅能回答常规问题,还能:
- 根据需要自主决定是否搜索网络信息
- 获取最新的互联网信息
- 抓取完整的网页内容进行深度分析
- 综合多个信息源生成更全面的回答
这样的助手在实际应用中具有很高的价值,可以帮助用户获取更准确、更全面的信息,而不仅仅局限于LLM训练数据中的知识。
未来改进方向
在接下来的学习中,还可以考虑以下方向的扩展:
- 历史会话管理:实现对话历史的保存和管理
- 多工具协同:集成更多工具,如文档解析等
- 记忆与学习:让助手能记住用户偏好和之前的交互
- UI集成:将助手集成到Web界面或其他应用中
通过Langgraph,我们看到了构建复杂AI工作流的强大可能性,它提供了一种灵活且可扩展的方式来组织和管理LLM的行为,使AI助手能够完成更加复杂的任务。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!