关于Chrome新版浏览器存储分区的技术前瞻(2023.10)
背景
事件说明:2023.10.25,第三方学习平台报障,PC端的报告页新开tab查看报告详情,被跳转到了登录页,用户在不登录的情况下无法查看报告详情。
排查过程:部分同事电脑的Chrome可以正常跳转,部分电脑的Chrome不可以,第一时间发现是版本不同,然后发现在浏览器存储里,低版本的Chrome(106.x)和高版本的Chrome(118.x)上显示有差异,在当时不确定具体原因的情况下做了如下修改,解决了报障问题:
解决方案:在pc端新打开tab的代码里,把token加到要打开的url后面,同时在app.vue里做url取token的处理,来获取userinfo信息。避免因为没有token,而被跳转到登录页。
此次线上报障虽然已经修复,但为了找到根本原因,以方便后续web开发的应用能够正常运行在不同版本浏览器,去到 Chrome官网了解到了如下信息:
Chrome版本差异
Chrome在最近几年的用户隐私上做了很多的技术提案以及功能上的开发探讨,此次问题的原因在于新版本Chrome浏览器增加了【分区存储】的机制,什么是分区存储?(点击文字可查看官网原文)
To prevent certain types of side-channel cross-site tracking, Chrome is partitioning storage and communications APIs in third-party contexts.
为了防止某些类型的旁路跨站点跟踪,Chrome正在第三方上下文中对存储和通信API进行分区。
Without storage partitioning, a site can join data across different sites to track the user across the web. Also, it allows the embedded site to infer specific states about the user in the top-level site using side-channel techniques such as Timing Attacks, XS-Leaks, and COSI.
如果没有存储分区,一个站点可以连接不同站点的数据,从而在整个Web上跟踪用户。此外,它还允许嵌入式站点使用侧信道技术(如定时攻击、XS泄漏和COSI)来推断顶级站点中用户的特定状态。
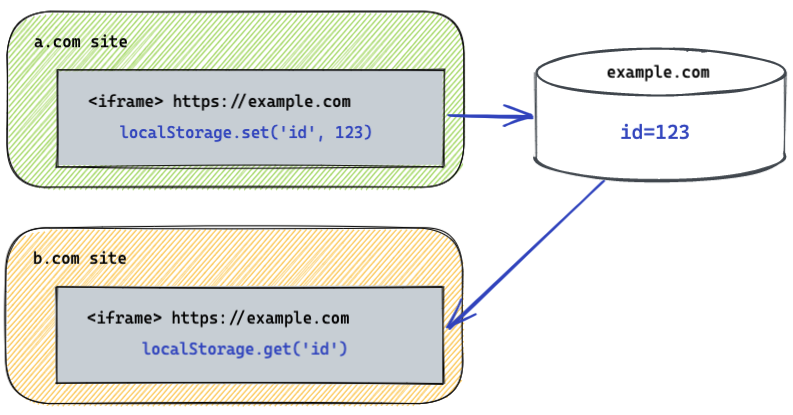
Historically, storage has been keyed only by origin. This means that if an iframe from example.com is embedded on a.com and b.com, it could learn about your browsing habits for those two sites by storing and successfully retrieving an ID from storage. With third-party storage partitioning enabled, storage for example.com exists in two different partitions, one for a.com and the other for b.com.
从历史上看,存储仅按来源进行监控。这意味着,如果example.com中的iframe嵌入到a.com和b.com中,它可以通过存储并成功从存储中检索ID来了解这两个网站的浏览习惯。在启用第三方存储分区的情况下,example.com的存储存在于两个不同的分区中,一个用于a.com,另一个用于b.com。
Partitioning generally means that data stored by storage APIs like local storage and IndexedDB by an iframe will no longer be accessible to all contexts in the same origin. Instead, the data will only be available to contexts with the same origin and same top-level site.
分区通常意味着存储API(如本地存储和IndexedDB)通过iframe存储的数据将不再可以访问同一来源的所有上下文。相反,数据将仅可用于具有相同来源和相同顶级站点的上下文。
最后一句话说明了重点:存储的数据只能在具有相同来源和相同顶级站点进行访问。
然后对于web开发来说,最常用的local storage和session storage受到了影响,如下说明:
The Web Storage API provides mechanisms by which browsers can store key/value pairs. There are two mechanisms: Local Storage and Session Storage. They are not currently quota-managed, but will still be partitioned.
Web Storage API 提供了浏览器可以存储键/值对的机制。有两种机制: 本地存储和会话存储。它们当前不受配额管理,但仍将被分区。
这句话里的不受配额管理,目前不确定是不是大小限制的机制有所修改,但存储分区这件事已经确定在115以上版本的Chrome上做了此机制,但实际测试,116版本也是可以访问的,可能只有升级到117或者118才有这个机制(个人判断)。
下图是官方介绍第三方站点嵌套某个站点,关于存储分区概念的图例:
存储分区版本之前:
存储分区版本之后:
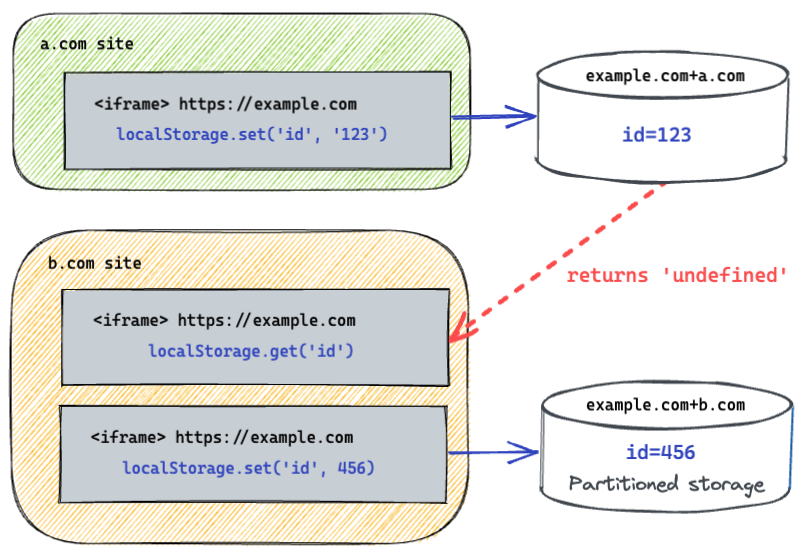
结合上图所示,如果一个第三方站点使用iframe的形式打开了a站点,a本身存储的数据会只存在该第三方站点+a站点下。
比如10月初a站点的scorm化,实际机制就等于是LMS平台作为顶级站点利用iframe的形式打开了a站点,这个时候存储的数据显示在118版本的浏览器上如下所示:
首先是scorm cloud这个平台的存储,有一个源地址:
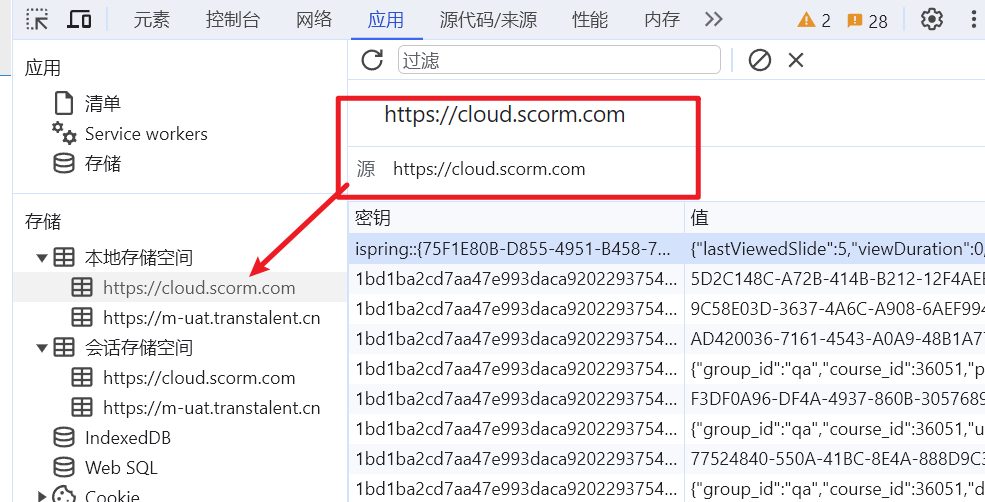
然后点击m-uat,比低版本的Chrome浏览器多了一个顶级站点和是否属于第三方的属性:
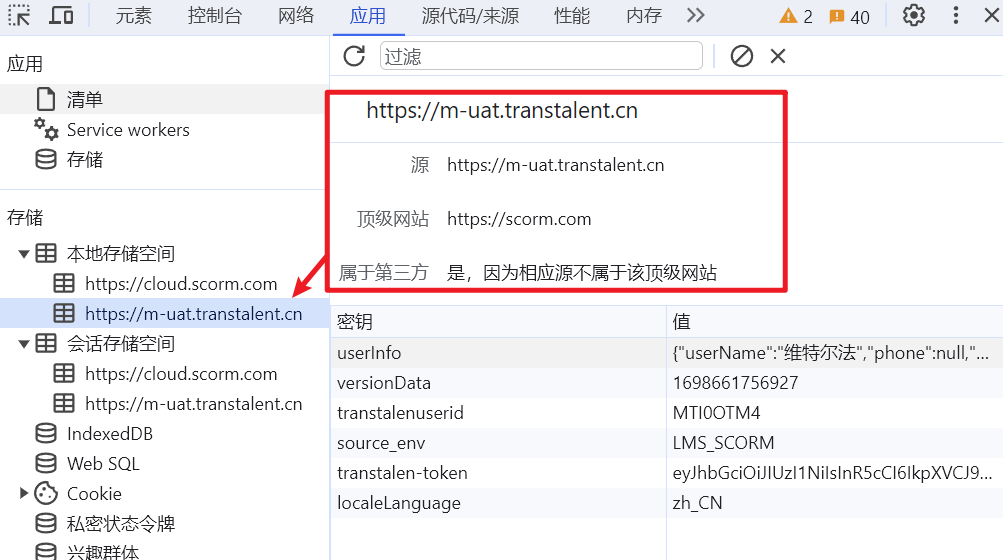
再根据官方图例的机制,此时在scorm cloud的站点下,存储的数据等于是在【https://cloud.scorm.com + https://abc.abc】的站点上,这个时候新开tab页访问DNA或者其他页面,实际是拿不到【https://abc.abc】这个缓存下的数据的。
所以此次报障的原因基本如上,最近几年关于用户信息在法律保护上越来越严格化,对于应用开发来说,需要跟随新技术或平台的机制做一些处理或技术方案升级。
存储分区的技术方案
官方技术方案
针对存储分区来说,并不是限制了以后任何情况下都不能跨站点访问数据了,而是有了新的API:share storage。
顾名思义,是在不同顶级站点下,分享自己站点的数据给其他顶级站点下的相同站点访问。
具体文档:https://github.com/WICG/shared-storage/blob/main/README.md#worklets-can-outlive-the-associated-document
但由于是新技术,目前未在项目上去做尝试,并且此API在市面上的浏览器并不通用:
(可见Chrome和Edge且只有117和118才有)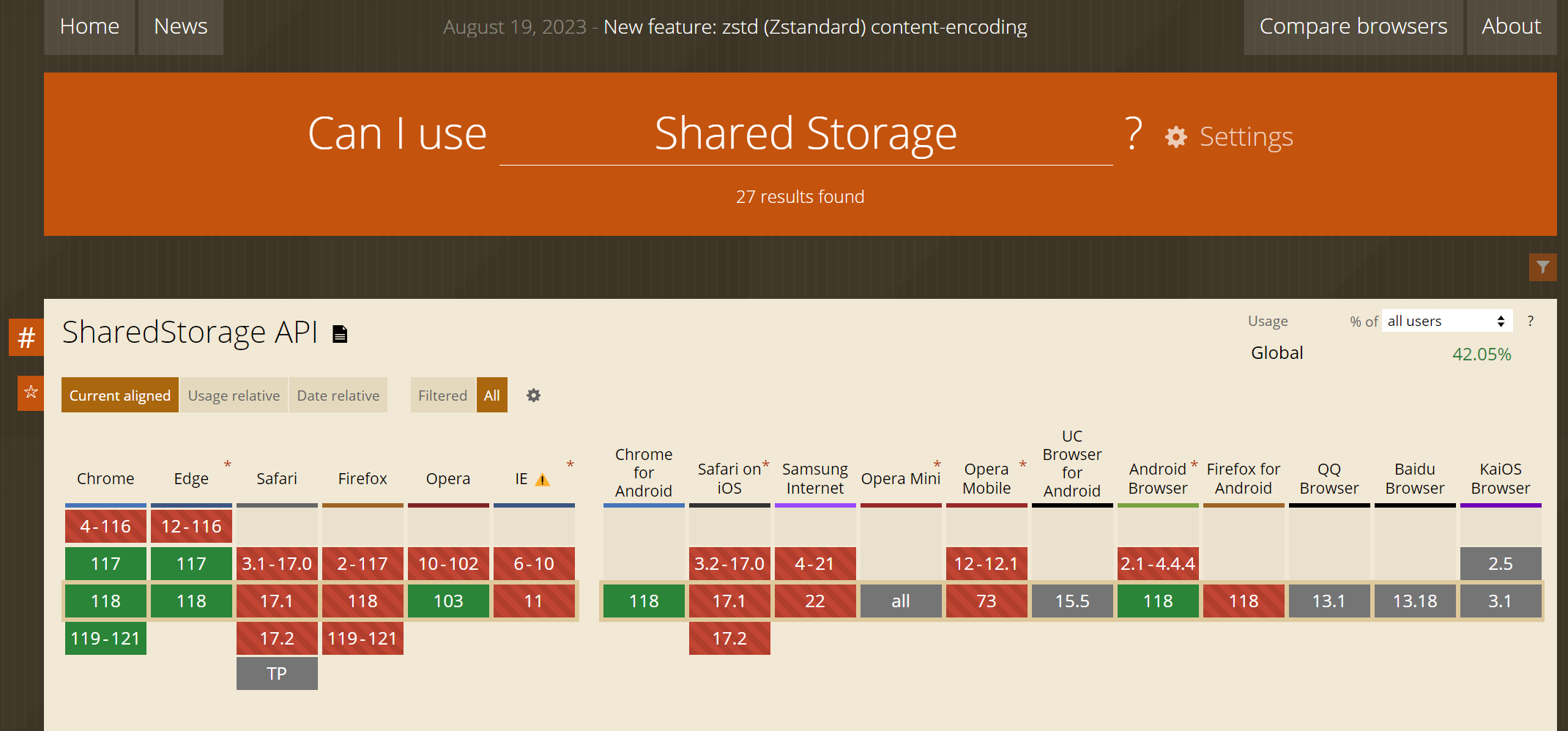
应用上的技术方案
假如后端服务已支持token机制,在大部分场景下可通过url中拼接token的方式来解决问题;
没有token机制?emmmm…..
写在结尾:
Chrome浏览器发版内容地址:
https://chromestatus.com/roadmap
https://chromestatus.com/features#milestone%3D118
如果有在本月或者本周把Chrome升级到最新版本的小伙伴,可以看下对应的应用是否需要做一些处理(主要是被第三方使用iframe打卡&&打开新tab的相同站点)。
由于本次只在Chrome上做了新技术了解,其他如firefox等浏览器也许也有各自的限制或技术升级,如果有小伙伴在开发期间了解到或应用到了新的技术,可以分享给大家,共同学习,共同进步~
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!